
Why Your Loss Curve Lies to You
A forensic examination of what training metrics actually encode — and the three failure modes nobody puts in their tutorial.
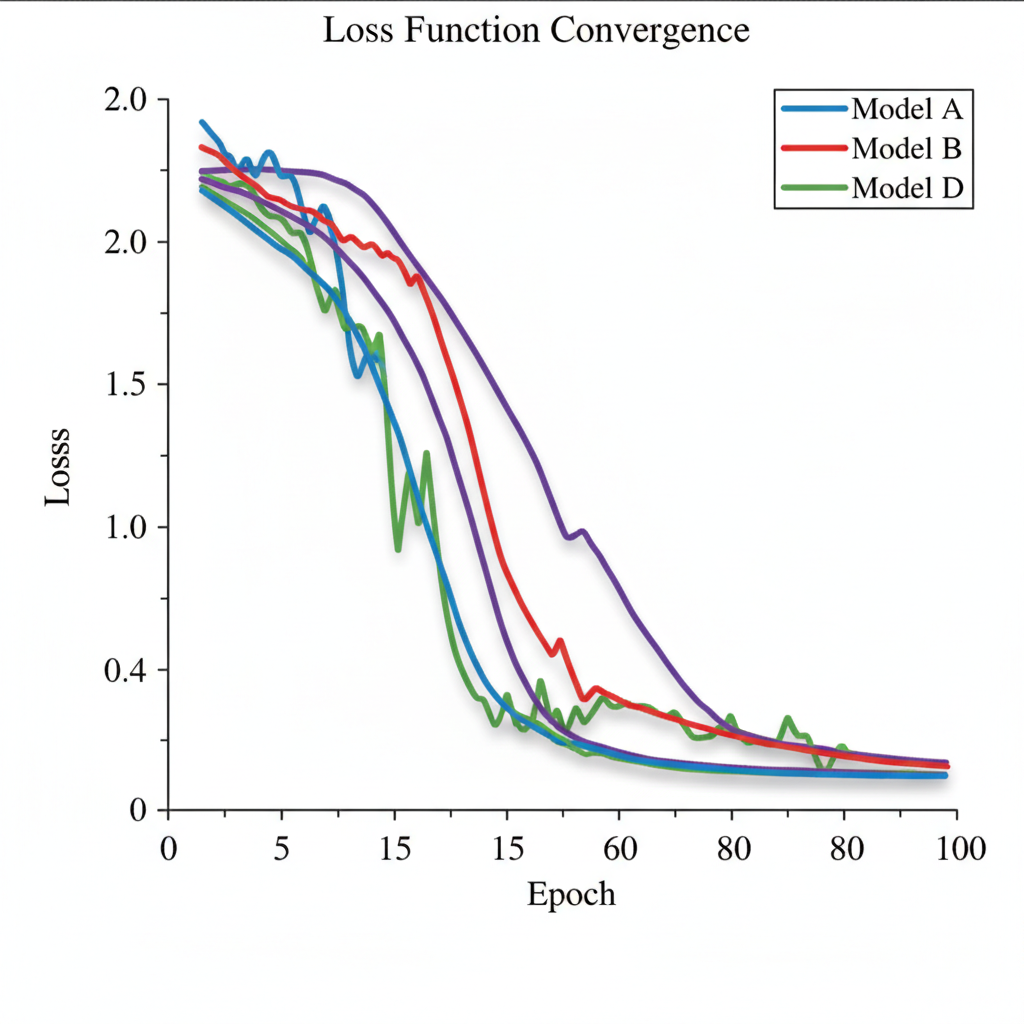
It was 2:17 a.m. when Priya messaged the team Slack. The model had been training for six hours. Loss: 0.0031. She typed: "I think we're done?" The next morning, the model predicted"cat" for every image in the validation set. Loss curves had lied to her — politely, consistently, and with complete statistical confidence.
The problem isn't the metric. Cross-entropy loss is a perfectly reasonable objective. The problem is the implicit assumption baked into how we read it: that lower is better in a way that generalizes. It doesn't, and understanding why requires a brief detour through what the loss function is actually optimizing.
Cross-entropy measures the average negative log-likelihood of the true labels under your model's predicted distribution. When it goes to zero, it means your model has assigned probability 1 to every correct label in the training set. This is not generalization. This is memorization wearing a lab coat.
The validation loss tells a different story — but only if you know how to read the divergence. A gap of 0.1 between training and validation at epoch 20 means something entirely different from the same gap at epoch 200 on the same architecture. Context is everything, and the curve alone has none.